昨天花了很多時間在介紹 embedding 跟弱化的 softmax(XX^T)X,如果昨天了解個大概那今天就不太會有問題。
文章參考及圖片來源: https://www.cnblogs.com/rossiXYZ/p/18751758 , https://zhuanlan.zhihu.com/p/410776234
核心觀念: 加權求和 → 根據目前的位置去關注序列中的其他位置,來取得有用的資訊。
後續延伸回到 Attention(Q, K, V) 公式

昨天有說到 Q, K, V 本質上都是由 x 轉換而來的,這個轉換是透過線性轉換 (程式對應 nn.Linear),以下用兩張圖來說明
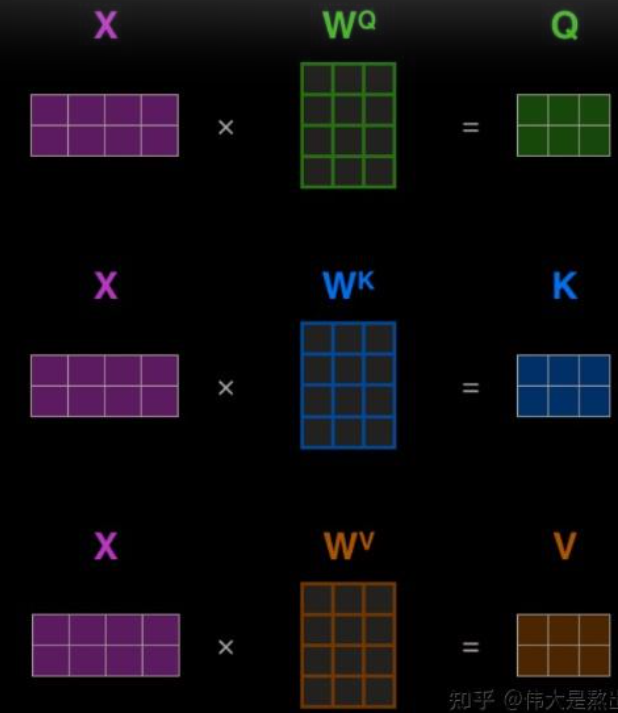
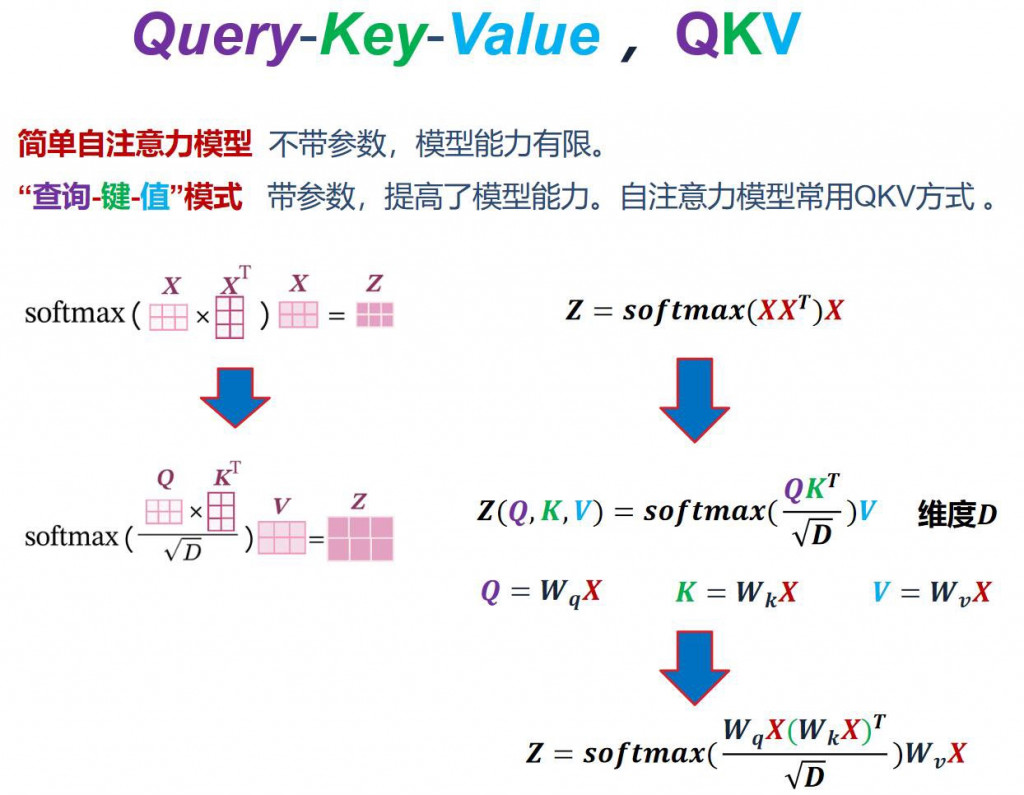
圖片來源: https://www.cnblogs.com/hbuwyg/p/16978264.html
Q: 為什麼不直接使用 X 而要透過線性變換呢 ??
A: 主要是為了模型擬合程度,W矩陣是可以訓練,可以提高模型能力
Q: Q, K, V 分別代表什麼意思 ??
A:
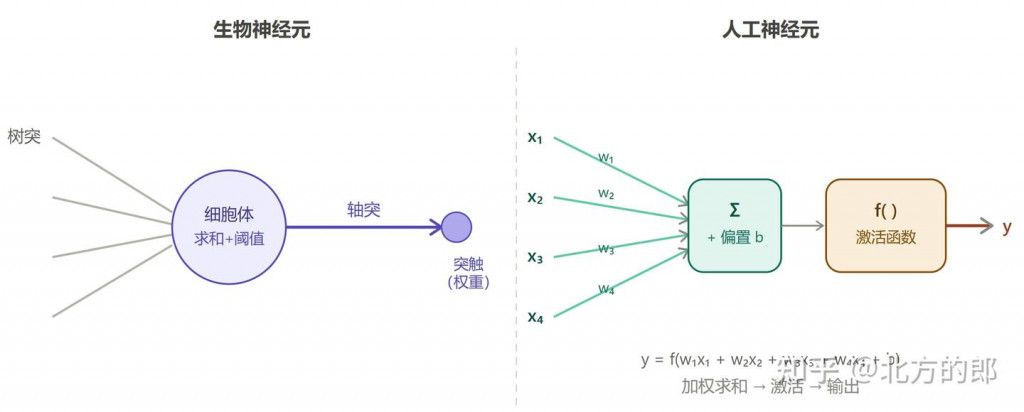
圖片來源: https://zhuanlan.zhihu.com/p/2020875711309776812
可以參考上圖,為了模擬我們大腦的神經元(每個神經元通過數千條突觸與其他神經元相連)的模式,我們使用右邊人工神經元,其中清綠色的部分對應到的就是 torch 當中的 nn.linear,指的是國中我們學過的線性方程式,y = Wx + B,所以圖中對應 nn.Linear(4, 1),前面 4 代表輸入,後面 1 代表輸出,當中的 W, B 矩陣就是模型做訓練學習的部分。
神經元當然不會只有一個輸出,所以會像下圖一樣有多數入多層,那中間的層我們稱之為 hidden layer (翻譯為隱藏層)。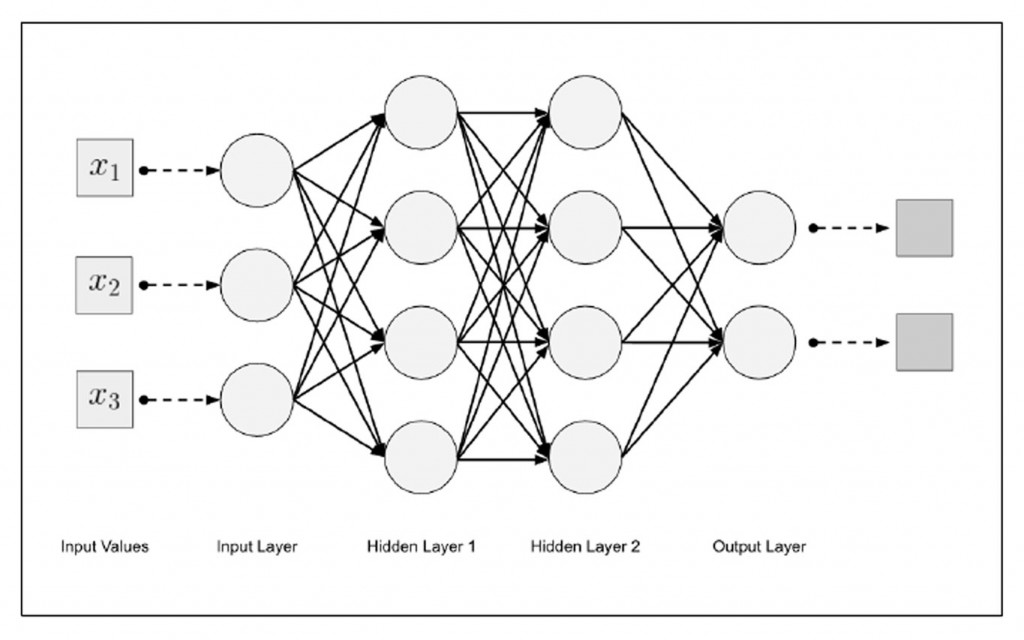
圖片來源: https://www.alpharithms.com/pytorch-linear-model-bias-parameter-523322
這裡我們可以先看一下大家都是怎麼取名的,大致上會分成以下四種
另外維度大小通常是以下名稱
這裡我們照幾個步驟完成,可以照著步驟一起想,先試著寫寫看,如果不行就先照打,確定可以之後再重來一次,這是我認為學最快的方式。
以下名稱採用 linear_q, 及 hidden_size
# step 1
import torch
from torch import nn
import torch.nn.functional as F
class MySelfAttention(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor):
'''
B: batch size
L: seq len
D: embedding dimension
x: (B, L, D) or (B, L, E) 簡寫每個都不太一樣
'''
return
# step 2
import torch
from torch import nn
import torch.nn.functional as F
class MySelfAttention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.linear_q = nn.Linear(hidden_size, hidden_size)
self.linear_k = nn.Linear(hidden_size, hidden_size)
self.linear_v = nn.Linear(hidden_size, hidden_size)
self.scaling = hidden_size ** -0.5
def forward(self, x: torch.Tensor):
'''
B: batch size
L: seq len
D: embedding dimension
x: (B, L, D) or (B, L, E) 簡寫每個都不太一樣
'''
return
# step 3
import torch
from torch import nn
import torch.nn.functional as F
class MySelfAttention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.linear_q = nn.Linear(hidden_size, hidden_size)
self.linear_k = nn.Linear(hidden_size, hidden_size)
self.linear_v = nn.Linear(hidden_size, hidden_size)
self.scaling = hidden_size ** -0.5
def forward(self, x: torch.Tensor):
'''
B: batch size
L: seq len
D: embedding dimension
x: (B, L, D) or (B, L, E) 簡寫每個都不太一樣
'''
query = self.linear_q(x)
key = self.linear_k(x)
value = self.linear_v(x)
# (B, L, D) dot (B, D, L) = (B, L, L)
attn_scores = torch.matmul(query, key.permute(0, 2, 1)) * self.scaling
attn_weights = F.softmax(attn_weights, dim = -1)
# (B, L, L) dot (B, L, D) = (B, L, D)
attn_output = torch.matmul(attn_weights, value)
return attn_output
if __name__ == "__main__":
model = MySelfAttention(64)
x = torch.rand(2, 100, 64)
y = model(x)
print(y.shape)
今天就以程式為主,花了點時間分成多個步驟,希望能讓你更好理解和實作,今天練完之後確定會,可以明天看著公式自己嘗試一次,相信沒多久你就會上手了,今天就先到這囉 ~~ 明天會有個小總結,來幫助你更了解。


 iThome鐵人賽
iThome鐵人賽